

The Rise of Edge Computing in Retail IT
As retail embraces digital transformation, the demand for real-time, localized intelligence is pushing compute power closer to where the action happens—on the store floor. Enter edge computing: the practice of processing data near its source instead of relying solely on centralized cloud infrastructure and costly cloud hosting dependencies.
In a retail setting, that means deploying compute resources directly within stores to handle data from barcode scanners, POS systems, weighing machines, cameras, and other IoT devices. The result? Faster insights, lower latency, and uninterrupted operations—even when the network isn’t cooperating.
While edge computing isn’t new, recent advances in Kubernetes, IoT, and AI have redefined what’s possible—making cloud-native architectures at the edge a powerful reality.
Speed, Resilience, and Relevance: Why Retail Needs Edge Now
Retail environments demand split-second responsiveness, seamless customer experiences, and operational resilience. Edge computing helps meet these needs by enabling:
- Sub-Second Transactions: Processing happens locally, minimizing dependence on external networks and cloud latency.
- Personalized In-Store Engagements: Customer data can be analyzed at the edge to serve relevant recommendations in real time.
- Offline Continuity: Stores stay operational—even during network outages—thanks to local processing and storage.
In a world where the physical and digital retail experiences must blend effortlessly, edge infrastructure is no longer optional. It’s a competitive necessity.
Kubernetes Edge Computing Platform Comparison
When building an edge architecture, not all Kubernetes options are created equal. Here’s how OpenShift Compact Clusters compare with other popular edge-native solutions like K3s and KubeEdge:
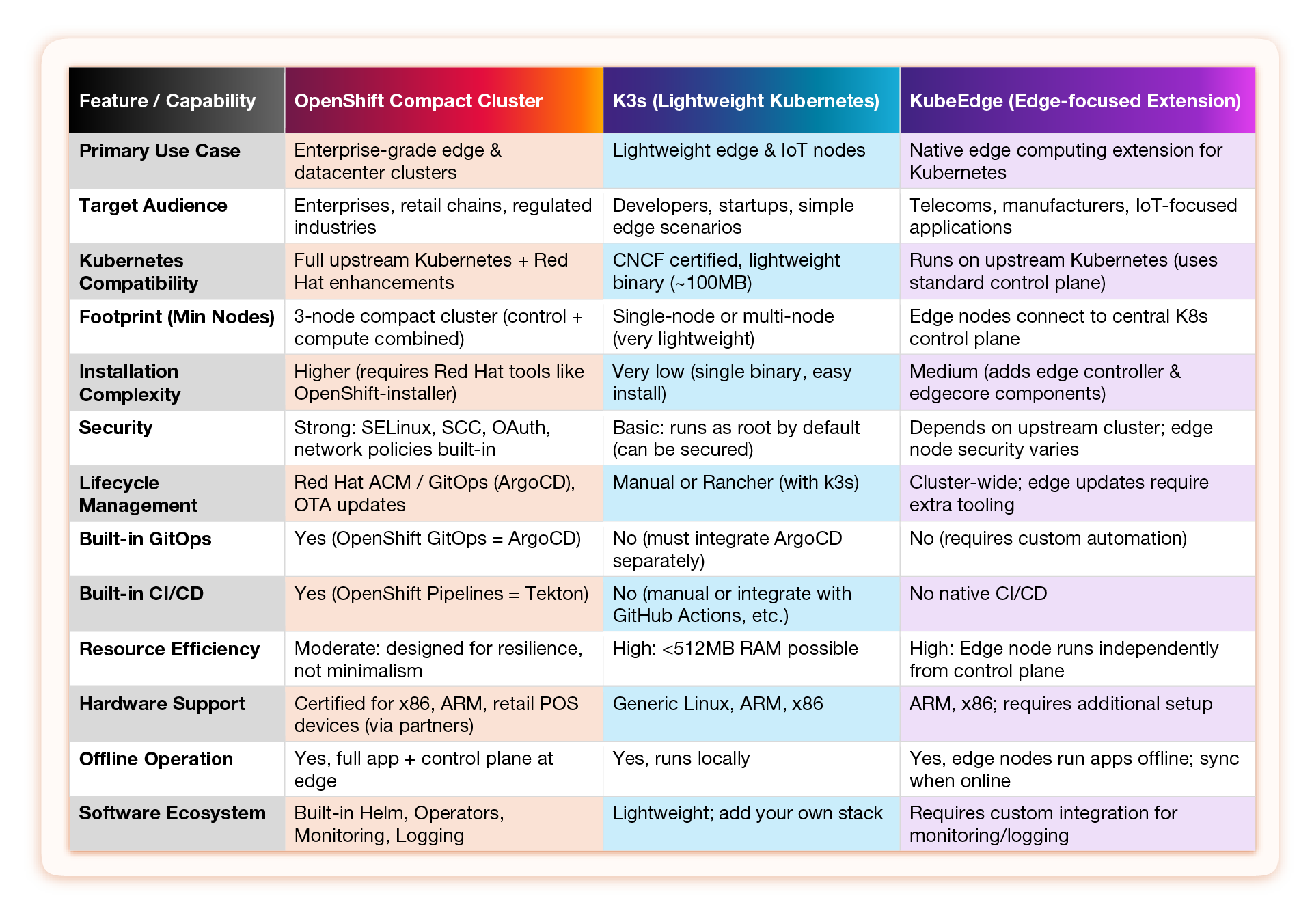
We found that for large-scale enterprise retail, OpenShift offered the right balance of robustness, security, and scalability—backed by commercial-grade support and lifecycle tooling.
OpenShift: Bringing Kubernetes to the Edge
Kubernetes was originally designed to manage large-scale cloud deployments. But with Red Hat’s OpenShift Compact Cluster—optimized for just three nodes—we can bring enterprise-grade Kubernetes capabilities to resource-constrained edge environments like retail stores. This architecture allowed us to deploy and operate containerized microservices directly at the store level.
We adopted this architecture to support the deployment and operation of containerized microservices directly in-store. Here’s what we’ve learned over the past few years— from design to deployment—about scaling Kubernetes at the edge.
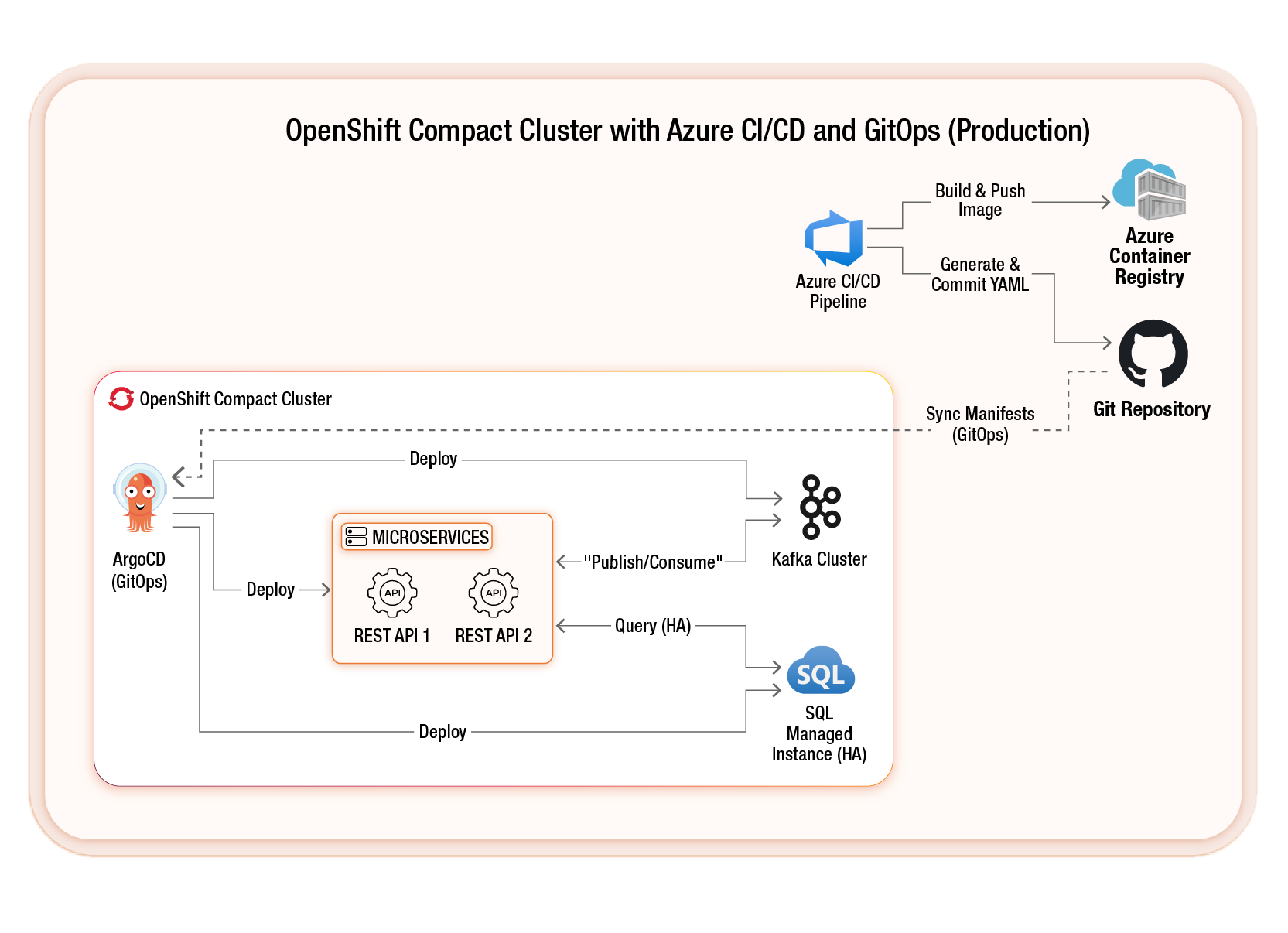
Our Edge Architecture: Components That Power Every Store
The architecture integrates CI/CD, GitOps, event streaming, data persistence, and observability—optimized for in-store edge deployment.
CI/CD and GitOps Integration
Azure DevOps handles continuous integration and builds container images for microservices such as retail apps, configuration apps and data sync services. It then stores these images in Azure Container Registry.
For continuous delivery, YAML manifests are committed into a Git repository, and deployments are orchestrated using OpenShift Pipelines or ArgoCD, depending on the use case. ArgoCD, following the App-of-Apps pattern, deploys applications across multiple OpenShift clusters. The OpenShift compact cluster above represents a single retail store.
OpenShift Compact Cluster
The OpenShift compact cluster includes three nodes running ArgoCD, retail microservices, a Kafka cluster, SQLMI, and monitoring software.
Kafka and Data Synchronization
Kafka enables asynchronous communication between microservices. It supports real-time data replication to SQL databases, avoiding the need for every transaction to fetch cloud-based data.
SQL Managed Instance (via Azure Arc)
SQL MI is deployed as a containerized workload within OpenShift and offers near-complete compatibility with SQL Server. This allows applications to access structured data locally, ensuring low latency and offline availability.
Monitoring and Observability
Though not shown in the architecture diagram, enterprise monitoring tools are deployed to ensure proactive system health tracking.
Real Results from Edge Deployment
Sub-Second Latency: Achieved <1s response times for key user operations like adding, updating, or deleting items from the cart.
High Availability: OpenShift’s compact cluster model ensured resiliency; the retail app remains operational even if one OpenShift node goes down. This allows the OpenShift team to upgrade or patch without causing an outage.
We run microservices and dependent software on multiple pods for scalability and resiliency.
Enhanced Security & Data Control: Sensitive transaction data remains within the store’s network, reducing external attack surfaces.
Portability Across Environments: Containerized applications can be easily moved across development, test, and production—simplifying deployment across store locations.
Efficient Resource Usage: Containers make optimal use of compute and memory resources, enabling more workloads on less hardware.
Simplified Updates and Rollbacks: Containers streamline version control, making it easy to update applications or revert changes with minimal disruption.
Multi-App Deployment: Multiple microservices can run on a single cluster, reducing hardware overhead while improving modularity and scalability.
Faster Store Setup: New stores can be configured rapidly using Helm charts and GitOps to replicate a standardized blueprint.
Remote Management: Software updates and deployments can be performed remotely through CI/CD pipelines and GitOps workflows—eliminating the need for on-site technical intervention.
Cost Efficiency: With most data processed and retained locally, retailers reduce reliance on cloud hosting and bandwidth—resulting in significant operational savings.
What’s Next: Innovations Unlocked by the Edge
With this architecture in place, we’ve unlocked significant innovation potential:
- Integration with IoT devices (e.g., smart price tags)
- Customer behavior analysis via video analytics
- Real-time recommendation engines based on local data
- Store-level AI/ML inference and decision-making
Beyond the Hype: Challenges of Scaling Edge Kubernetes in Retail
While the architecture has proven effective, a few challenges remain:
Complexity: Kubernetes, Kafka, and distributed microservices require skilled engineers for setup and ongoing support.
Resource Demands: Java-based components like Kafka remain resource-intensive, and the expectation of “lightweight edge compute” can be misleading.
Operational Overhead: Managing hundreds of OpenShift clusters requires a dedicated infrastructure and DevOps team for updates, monitoring, and incident management.
Conclusion: Edge is No Longer a Nice-to-Have—It’s Retail’s New Core
Deploying OpenShift compact clusters for edge computing in retail has met—and in many cases, exceeded—our initial expectations. It has brought cloud-native agility, speed, and resilience to the store floor —without over-dependence on cloud hosting— while maintaining data security and control.
That said, organizations must be prepared for the operational complexity and resource demands that come with distributed, containerized infrastructure. With the right tooling and team in place, edge computing powered by Kubernetes is a transformative force for retail innovation.



